Redis 数据结构
Redis 是如何通过数据结构设计,系统性地解决高性能状态访问问题的?
一、设计第一性原理:Redis 的世界观
在讨论具体数据结构之前,必须先明确 Redis 的设计前提。
1.1 核心约束条件(不变前提)
内存是第一稀缺资源 Redis 是以内存为主的系统,任何设计都优先考虑内存占用。
访问延迟必须可预测且极低 设计目标不是“吞吐最大化”,而是“单次访问足够快”。
大多数操作应为 O(1) 或接近 O(1) 最坏情况可以存在,但不应成为常态路径。
系统应服务于真实访问模式,而非数据抽象的完美性 Redis 的数据结构不是“学术最优”,而是“工程最优”。
1.2 Redis 的核心设计哲学
可以将 Redis 的设计哲学抽象为四句话:
- **用数据结构表达业务语义**
- **用空间换时间是常态而非例外**
- **将一次性成本摊平到多次操作中**
- **允许结构演进,而不是一次设计到位**
后文的所有数据结构,都是这些哲学在不同场景下的具体体现。
二、Redis 不是“数据类型集合”,而是“访问模型集合”
传统视角下,我们常说 Redis 有五种数据类型:string、hash、list、set、zset。
但从架构视角看,更本质的划分是:
Redis 提供了一组“状态访问模型”,每种模型针对一种典型访问模式进行优化。
2.1 访问模型总览
| 访问模式 | 主要诉求 | 对应结构 |
|---|---|---|
| 单值快速访问 | 极低延迟 | String |
| 字段级随机访问 | O(1) 定位 | Hash |
| 顺序写入 + 遍历 | 插入频繁 | List / Quicklist |
| 去重 + 集合运算 | 成员唯一性 | Set |
| 有序 + 范围查询 | 排序与区间 | Sorted Set |
这些结构并非彼此竞争,而是在不同约束条件下的最优解。
三、String:最基础的状态单元
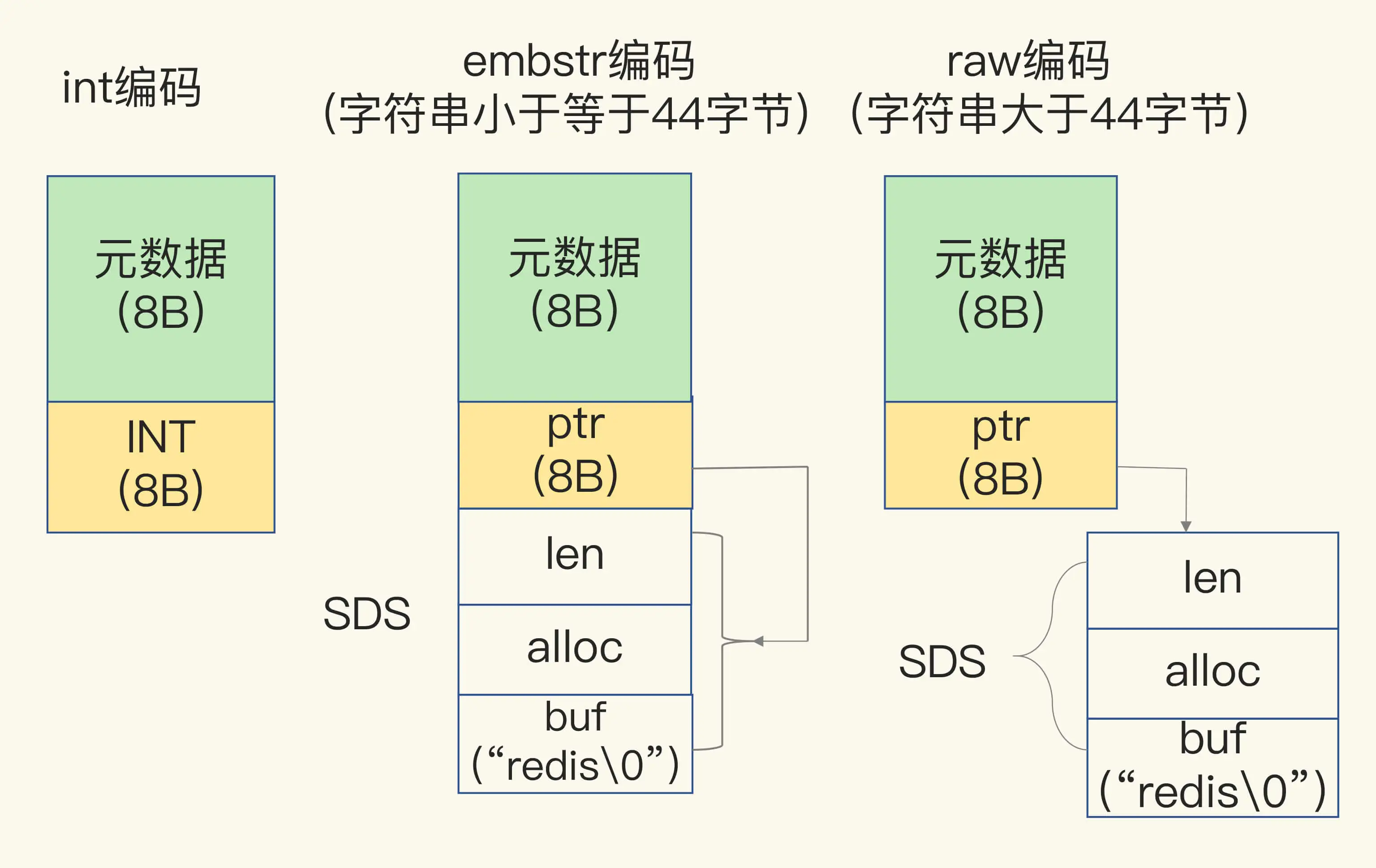
3.1 本质抽象
String 是 Redis 中最小、最通用的状态表达单元。
其本质并非“字符串”,而是:
一段二进制安全的字节序列(byte array)
Redis 不理解其语义,只负责高效存取。
3.2 支撑的访问模式
- 整体读 / 写
- 数值自增(原子计数)
- 位级访问(Bitmap)
这些能力共同覆盖了:
- KV 缓存
- 计数器
- 限流
- 状态标记
3.3 关键设计权衡
- **Embedded String**:短字符串直接与对象头连续存储
- **避免二次内存分配与指针跳转**
这体现了 Redis 的核心哲学之一:
减少一次间接寻址,胜过任何微小算法优化
四、Hash:对象属性的状态映射
4.1 本质抽象
Hash 并不是“嵌套结构”,而是:
一个 key 下的多个子状态的并列存储
它解决的问题是:
- 不希望为每个字段创建一个 Redis key
- 但仍希望 O(1) 访问单个字段
4.2 工程意义
- 减少 key 数量
- 提升局部性
- 降低内存与管理成本
这使 Hash 成为:
- 用户对象
- 配置对象
- 状态快照
的理想选择。
五、List / Quicklist:顺序状态的工程解
5.1 访问模型
List 服务的不是“数组”,而是:
高频插入 + 顺序遍历的状态序列
例如:
- 消息流
- 时间线
- 操作日志
5.2 从 Ziplist 到 Quicklist 的演进
这一演进体现了 Redis 的工程哲学:
| 阶段 | 优点 | 暴露问题 |
|---|---|---|
| Ziplist | 极省内存 | 插入导致连锁更新 |
| Quicklist | 分块隔离 | 结构复杂 |
| Listpack | 消除 prevlen | 编码复杂 |
本质规律:
当数据规模增长时,必须引入结构分层来隔离变化成本
六、Set:无序且唯一的状态集合
6.1 本质抽象
Set 表达的是:
“成员是否存在”这一布尔状态集合
而不是列表或映射。
6.2 典型价值
- 去重
- 成员关系判断
- 集合运算(交并差)
这些能力让 Set 成为推荐系统、标签系统的重要工具。
七、Sorted Set:有序状态与范围访问
7.1 本质抽象
Sorted Set 解决的是一个复杂但常见的问题:
在可排序的状态集合中,既要快速定位,又要高效范围查询
7.2 组合结构的哲学
ZSet 同时使用:
- Hash:O(1) 定位成员
- SkipList:O(logN) 范围遍历
这是 Redis 中最经典的结构组合设计:
用不同结构分别优化不同访问路径
八、内部结构共性原则
无论是 SDS、dict、quicklist 还是 rax,它们都遵循相同原则:
- **连续内存优先**
- **元数据最小化**
- **渐进式变更(如 rehash)**
- **为常见路径优化,而非极端情况**
这些原则比任何具体实现都更值得被记住。
九、Redis 的职责边界与反例
9.1 Redis 能做什么
- 高速状态缓存
- 会话状态存储
- 原子计数
- 实时排序
9.2 Redis 不适合什么
- 强一致事务系统
- 可靠消息队列(Pub/Sub 不可回溯)
- 长期权威数据存储
Redis 是“状态加速器”,而不是系统真相源。
十、可迁移的系统设计启示
- 数据结构是系统性能的第一生产力
- 延迟应被摊平,而不是集中爆发
- 不要为小概率牺牲高频路径
- 允许结构随规模演进
- 好的系统设计一定“偏心”
关联内容(自动生成)
- [/中间件/数据库/redis/Redis.html](/中间件/数据库/redis/Redis.html) 介绍了Redis的整体架构和基本概念,与数据结构章节形成完整的Redis知识体系
- [/中间件/数据库/redis/持久化.html](/中间件/数据库/redis/持久化.html) 介绍了Redis的持久化机制,与数据结构章节共同构成Redis核心技术的完整视图
- [/中间件/数据库/redis/集群.html](/中间件/数据库/redis/集群.html) 介绍了Redis集群架构,与数据结构章节共同构成Redis分布式系统的完整知识体系
- [/中间件/数据库/redis/复制.html](/中间件/数据库/redis/复制.html) 介绍了Redis的复制机制,与数据结构章节共同构成Redis高可用性的完整理解
- [/算法与数据结构/基本数据结构.html](/算法与数据结构/基本数据结构.html) 介绍了基础数据结构原理,为理解Redis内部数据结构实现提供理论基础
- [/算法与数据结构/散列表.html](/算法与数据结构/散列表.html) 介绍了散列表原理,与Redis的Hash数据结构实现密切相关
- [/算法与数据结构/树.html](/算法与数据结构/树.html) 介绍了树结构,与Redis的SkipList等有序数据结构实现相关
- [/软件工程/架构/系统设计/缓存.html](/软件工程/架构/系统设计/缓存.html) 介绍了缓存系统设计原则,与Redis作为缓存中间件的应用场景密切相关
- [/中间件/数据库/索引.html](/中间件/数据库/索引.html) 介绍了数据库索引原理,与Redis数据结构的访问模式和性能优化相关
- [/软件工程/性能工程.html](/软件工程/性能工程.html) 介绍了性能工程原则,与Redis数据结构设计的性能考量密切相关